Activity 17: Neural Networks
🕑04:41, 28 Nov 2019
Function fitter
For this activity [1], we will first explore the applications of a neural network---or more accurately,
a multilayer perceptron (MLP)---as a universal function fitter. Designing a neural network architecture can be quite
tedious as there are a lot of hyperparameters to tune in order for you to get desired results. After several attempts of
trial-and-error, I ended up with the network shown in Fig. 1 (all network
visualizations were done using [2]). For the training data, I generated 1000 random numbers distributed
uniformly in the range
- linear:
- quadratic:
- cubic:
- logistic sigmoid:

Figure 1: Network architecture for the function fitter.
The first hidden layer of the network contains 500 nodes, which are all activated by a rectified linear unit (ReLU), defined by
The second hidden layer contains 10 nodes, also activated by ReLU. The output layer is a single node which maps
everything calculated so far to a single output value. Thus, the function arguments (random numbers
where
For the test data, I generated 1000 equally-spaced numbers in the range
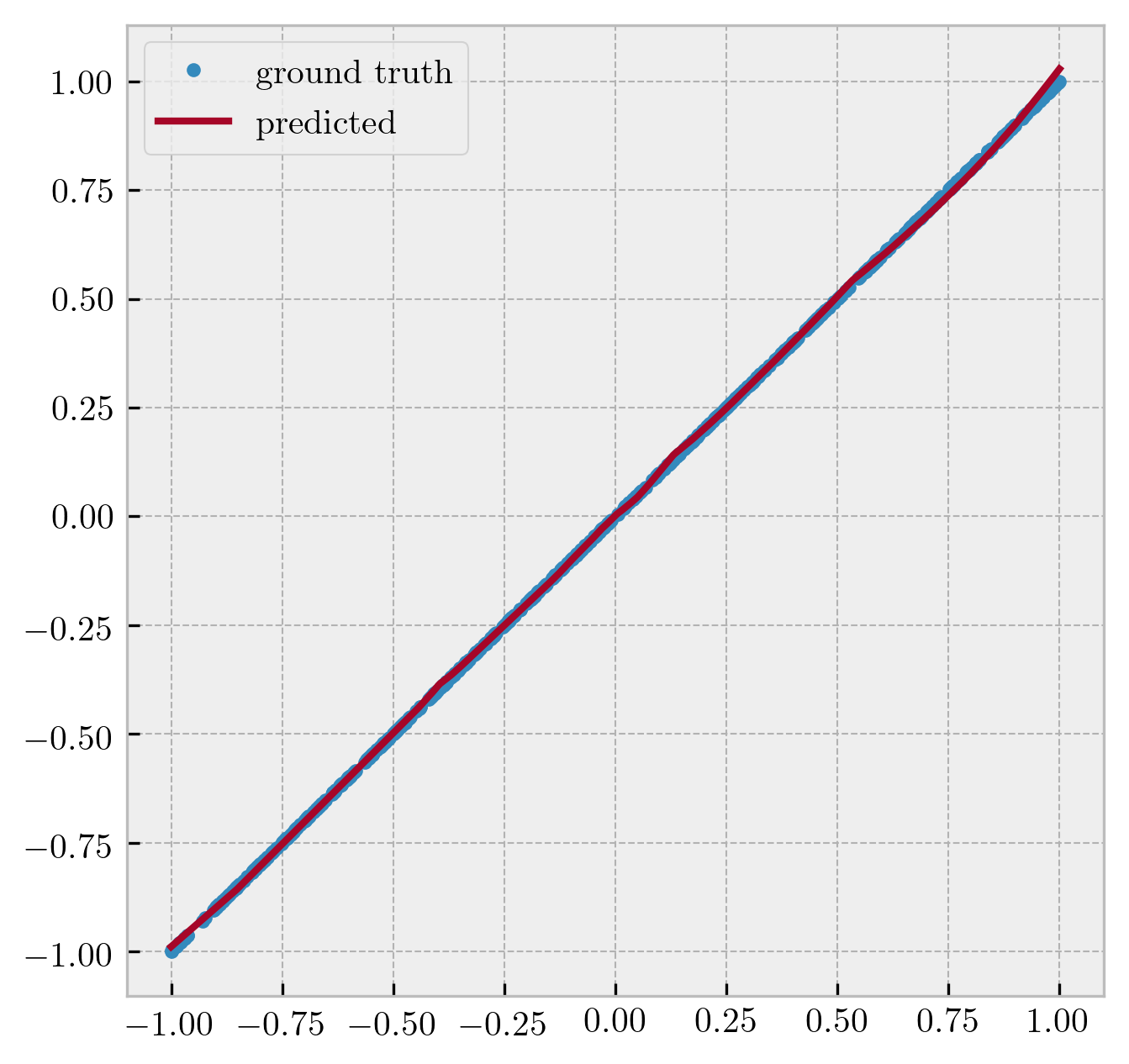
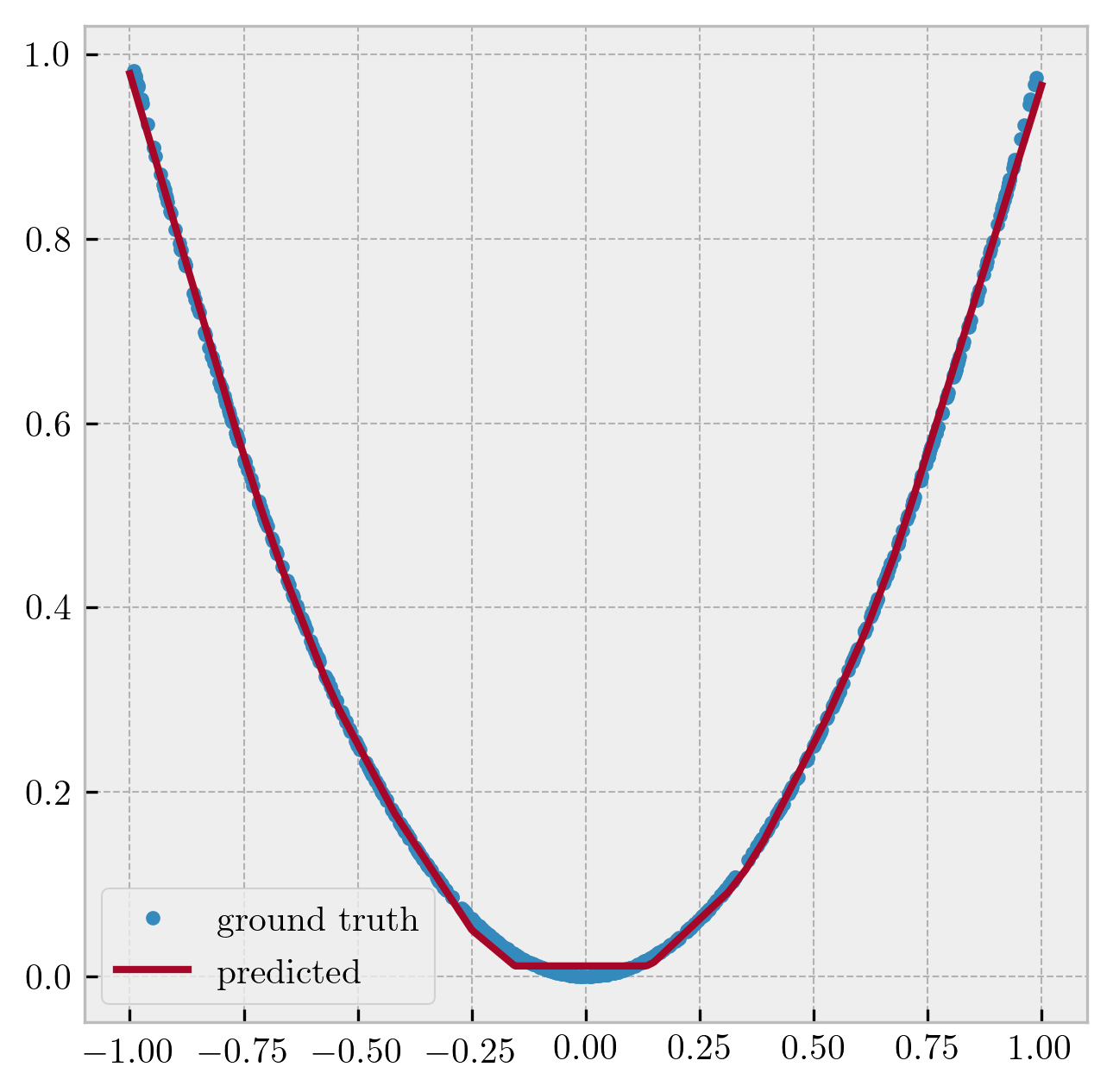
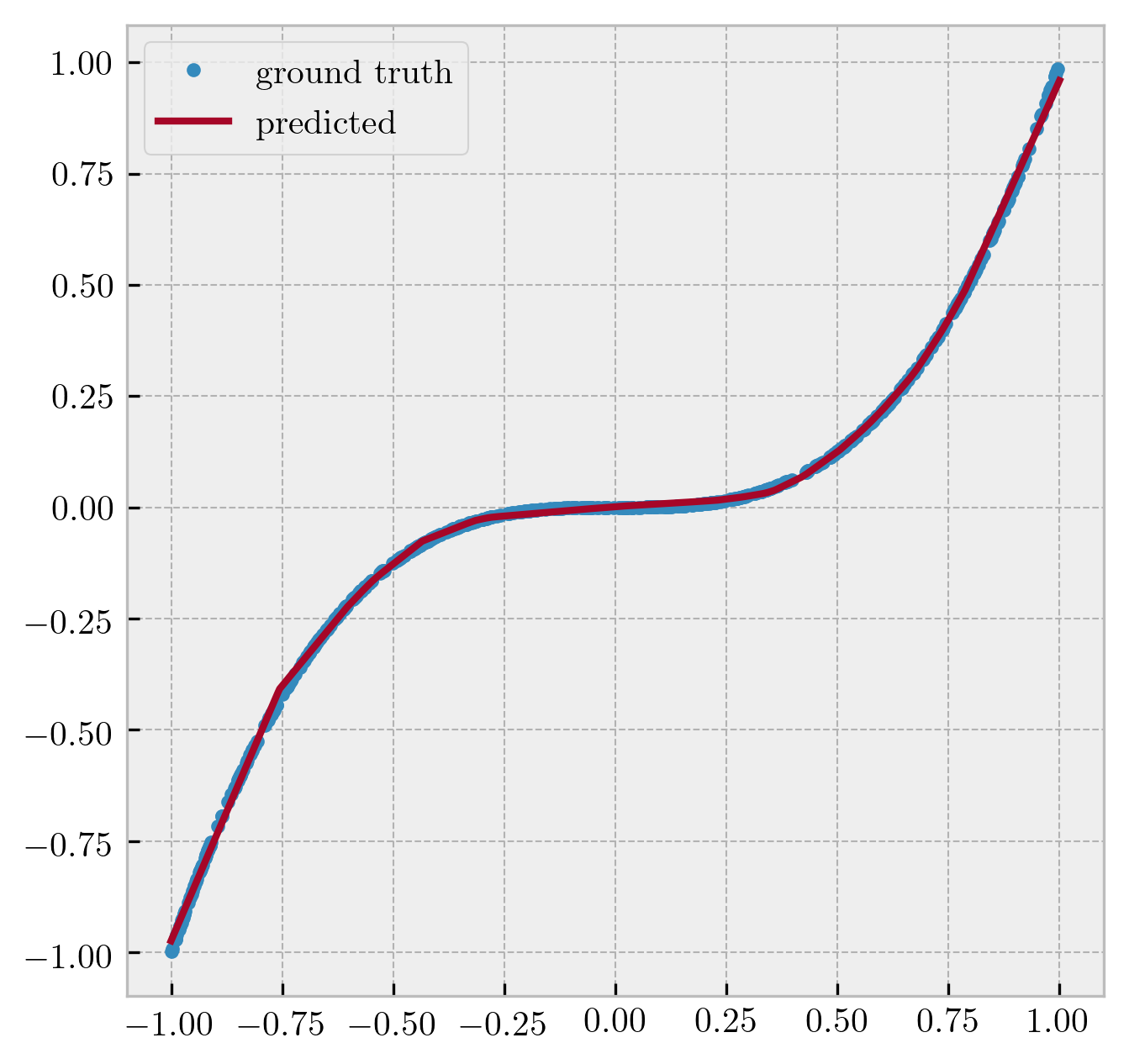



Figure 2: Neural network as a universal function fitter.
Fruit classification
For this section, I used my extracted
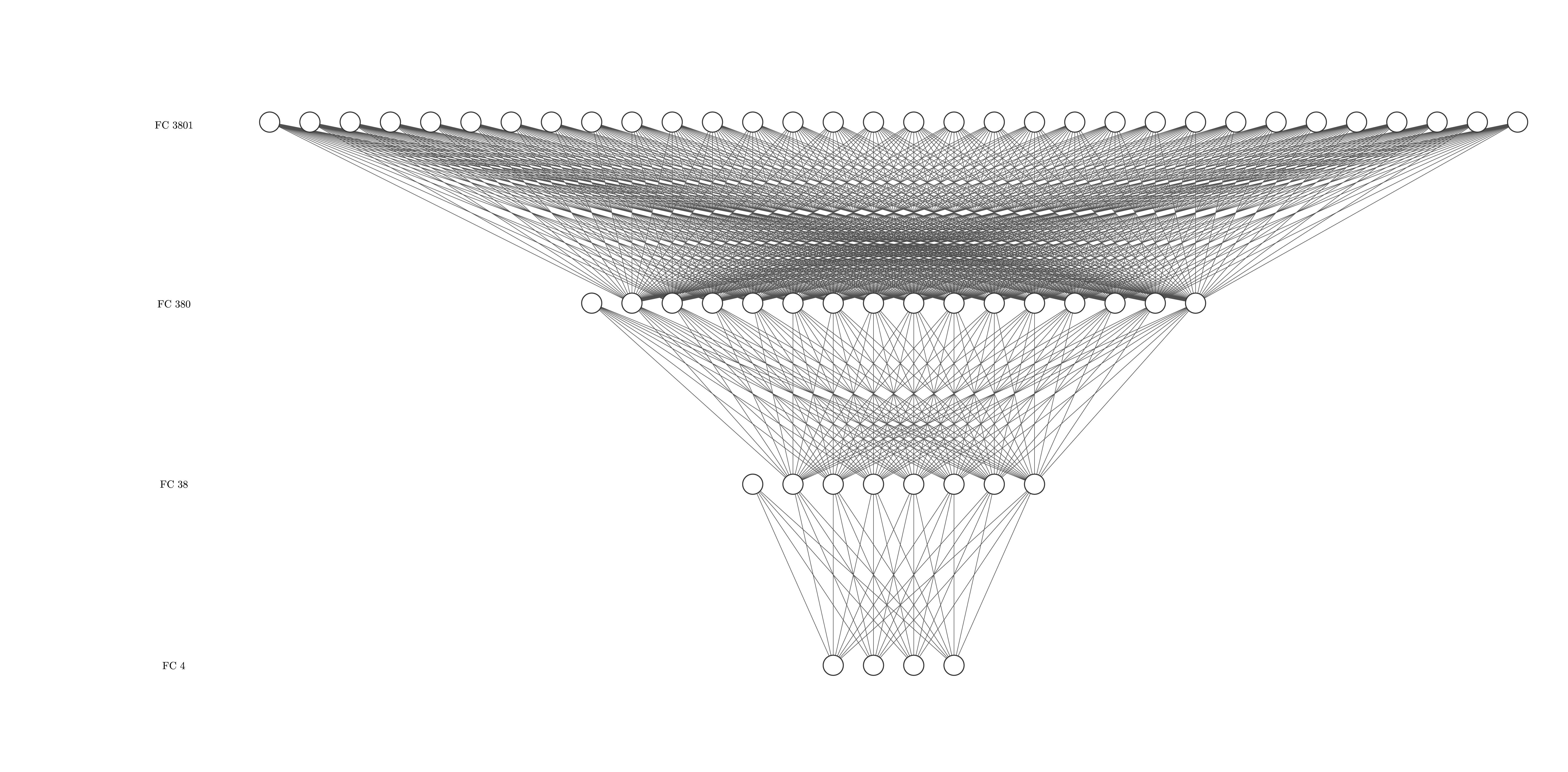
Figure 3: Network architecture for the fruit classifier.
The network was designed such that the first hidden layer contains as many nodes as data points. Layers are added which
contain
and the output layer is activated by a softmax, defined by
which outputs probabilities such that the sum of the output nodes should equal unity. Thus, for this dataset, the
network topology is 120-12-3 (two hidden layers, 3 nodes in output layer).
This time, the network objective is to minimize the mean-squared error (MSE), and the network is trained until it drops below a value of 0.01. Feeding in the test data shows a test accuracy of 100%, and the decision boundaries are shown in Fig. 4. This is not surprising since the fruit feature vectors form distinct clusters and do not overlap.
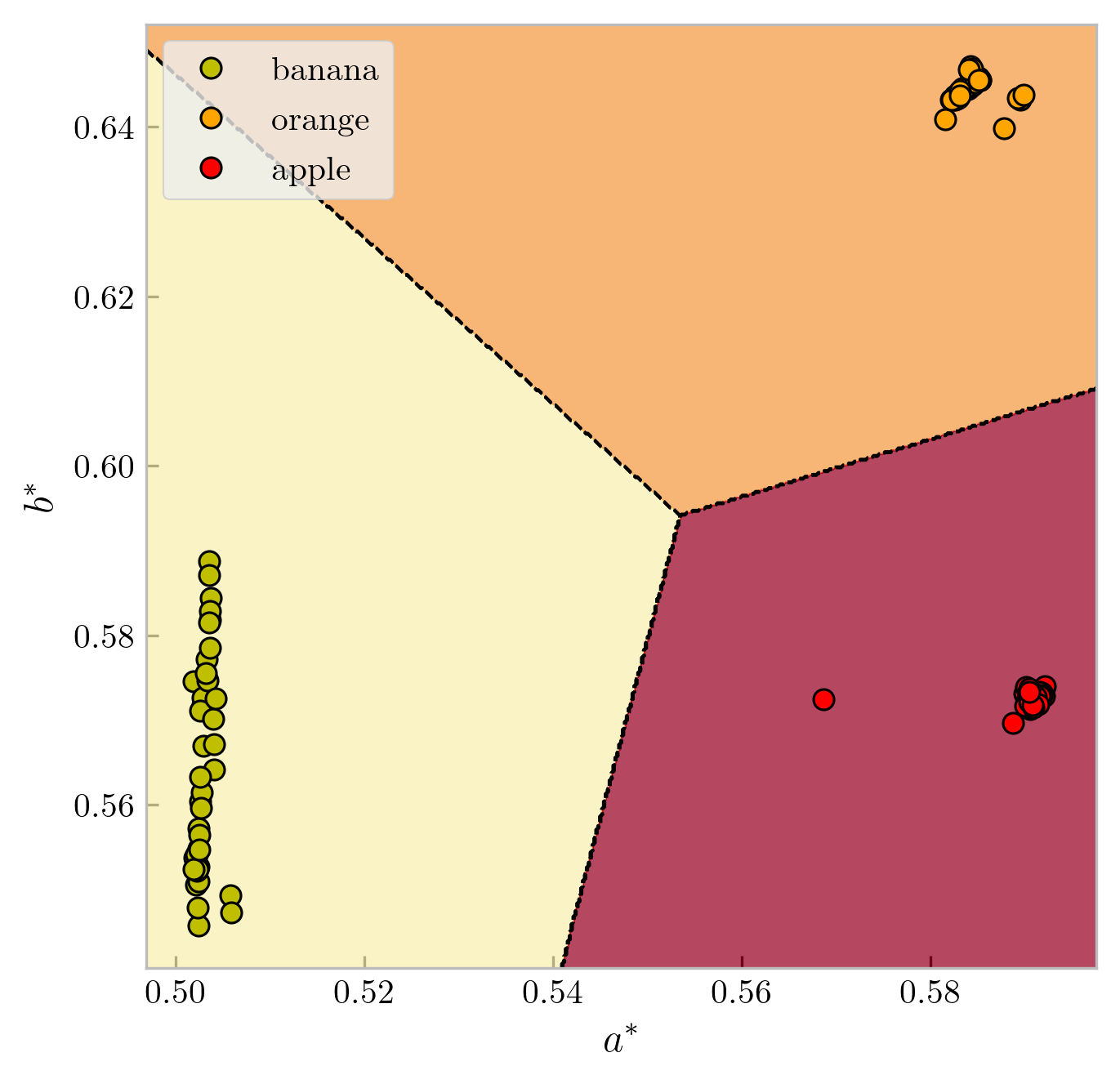
Figure 4: Decision boundaries for bananas, apples, and oranges in
Now, let’s consider adding more samples to the training/testing sets. Using the fruits dataset from [3],
I added more varieties of apples, bananas, and oranges, as well as an additional class of cherries.
Figure 5 shows the distribution of their feature vectors in
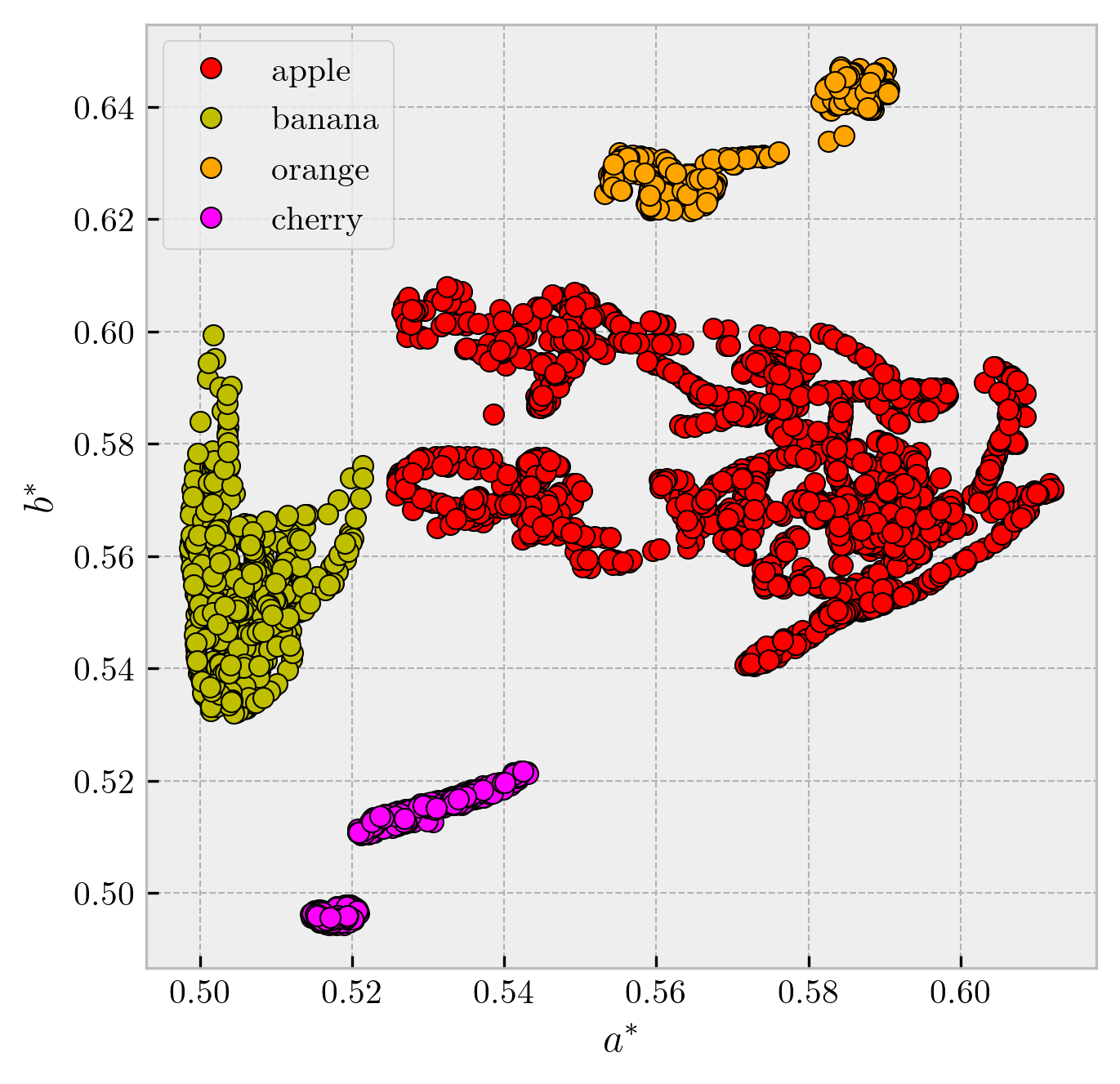
Figure 5:
With a total of 4752 feature vectors, I split the data 50-50 among the train-test sets. Therefore, the network topology
now is 2376-237-23-4 (3 hidden layers, 4 output nodes). Plugging in the test data afterwards yields a test accuracy of
99.96%, and the decision boundaries are shown in Fig. 6.
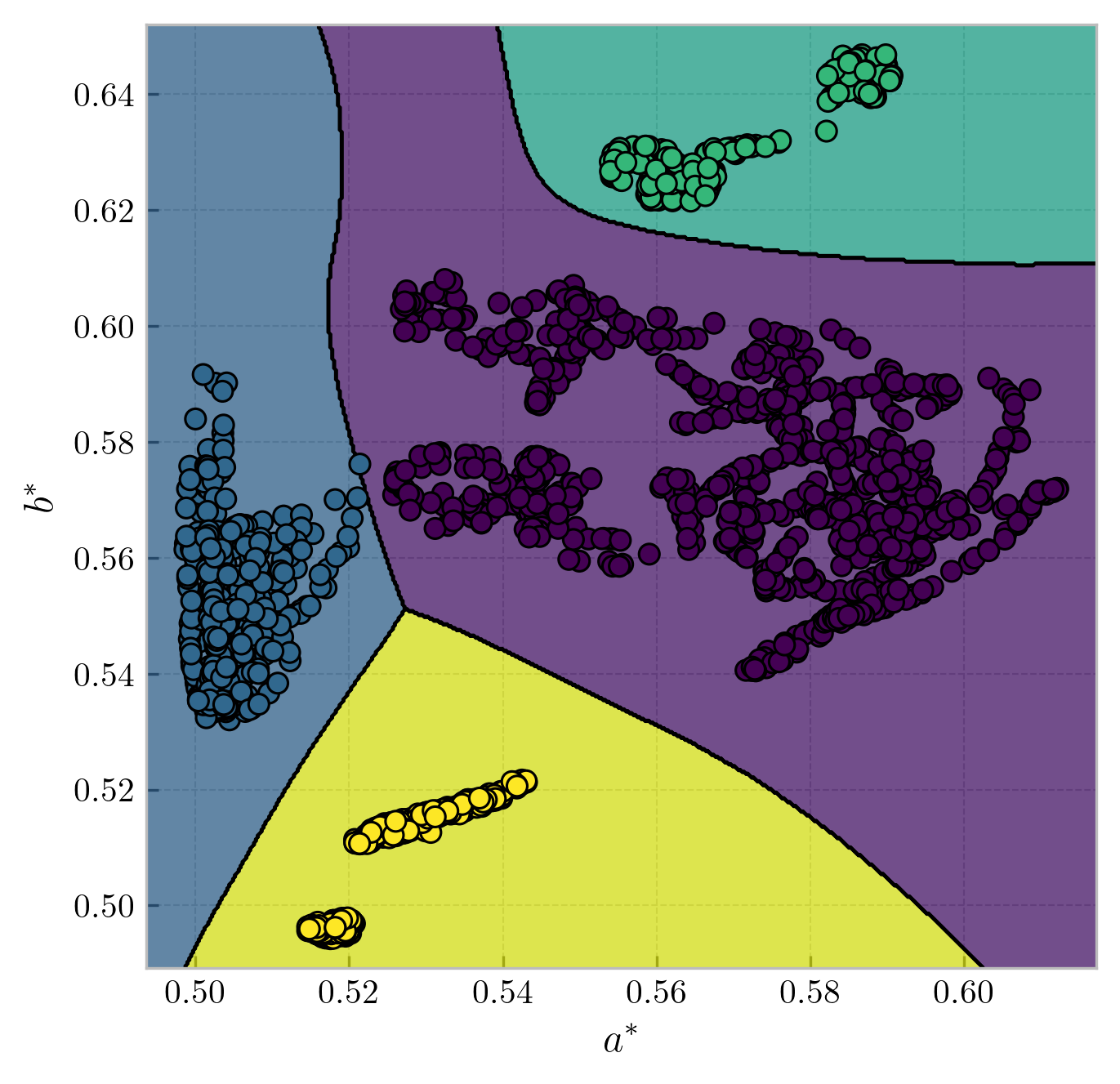
Figure 6: Decision boundaries for bananas, apples, oranges, and cherries in
References
- M. N. Soriano, A17 - Neural networks (2019).
A. LeNail, Publication-ready neural network architecture schematics, Journal of Open Source Software 4(33) 747 (2019).
H. Muresan, and M. Oltean, Fruit recognition from images using deep learning. Acta Univ. Sapientiae, Informatica 10(1), 26-42 (2018).