Activity 12: Feature Extraction
🕑12:02, 24 Oct 2019
For this activity [1], I obtained the Fruits-360 dataset from Kaggle [2] which contains thousands of labeled fruit images under the same lighting and capture settings but with varying angles. I took 50 samples each from the set of apples, oranges, and bananas.
Feature extraction:
I first imported the images into Python and converted them to
Feature extraction: eccentricity
Using the same images, I applied Otsu’s method since the images contain only one fruit on a plain white background. Each
fruit is then easily detected as a single large blob. I then used the regionprops function to extract the eccentricity
property from each detected blob. An
Discussion
Figure 1 shows the feature space of the selected dataset in
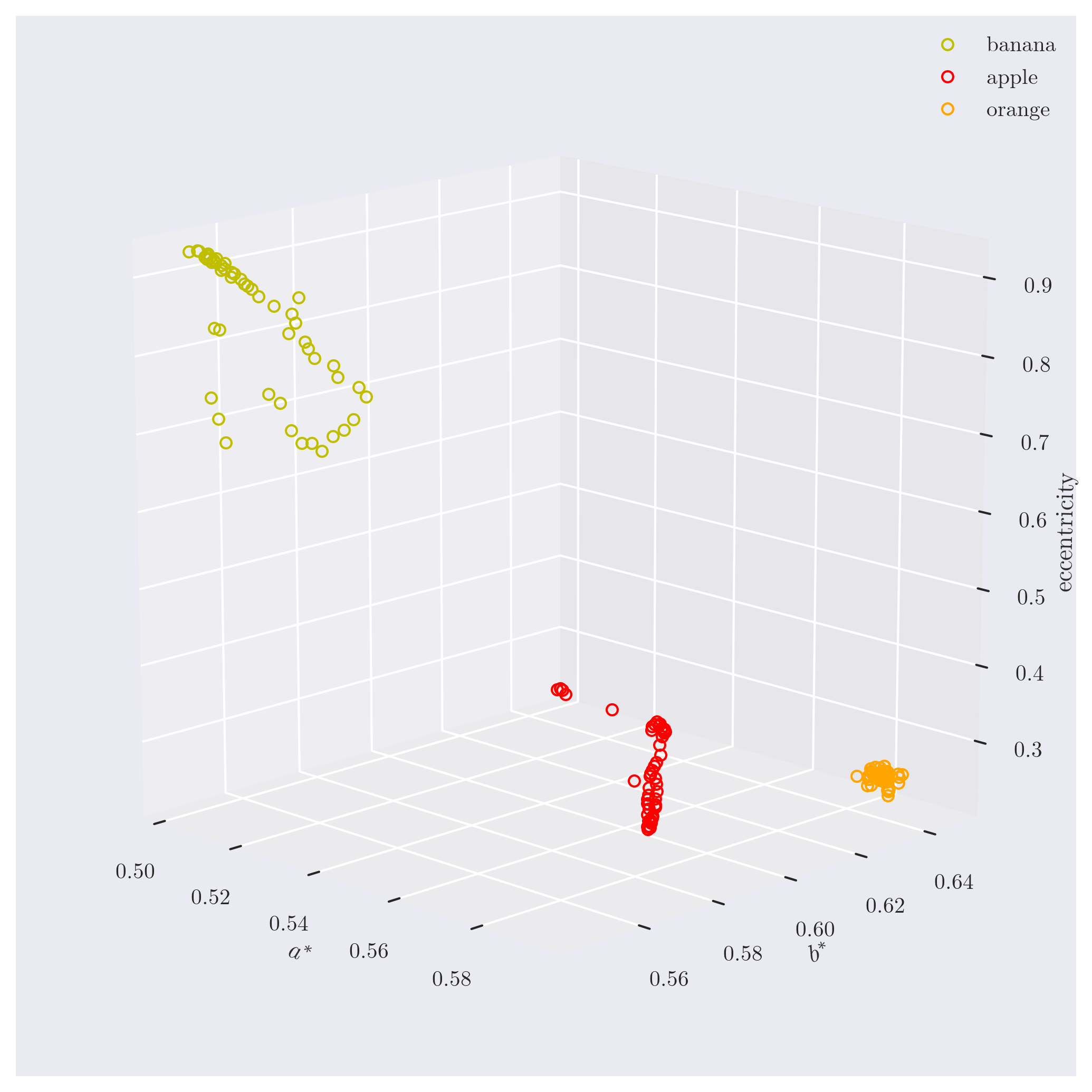
Figure 1: Feature space in



Figure 2: Feature space projections on different planes.
References
- M. N. Soriano, A12 - Feature extraction (2019).
H. Muresan, and M. Oltean, Fruit recognition from images using deep learning. Acta Univ. Sapientiae, Informatica 10(1), 26-42 (2018).